 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Medical Semantic-Assisted Transformer for Radiographic Report Generation
Aug 22, 2022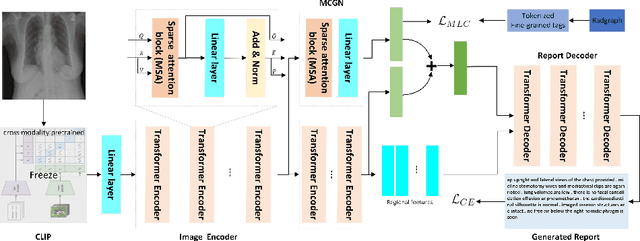
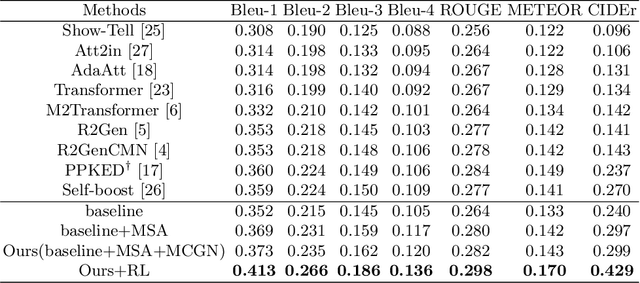

Automated radiographic report generation is a challenging cross-domain task that aims to automatically generate accurate and semantic-coherence reports to describe medical images. Despite the recent progress in this field, there are still many challenges at least in the following aspects. First, radiographic images are very similar to each other, and thus it is difficult to capture the fine-grained visual differences using CNN as the visual feature extractor like many existing methods. Further, semantic information has been widely applied to boost the performance of generation tasks (e.g. image captioning), but existing methods often fail to provide effective medical semantic features. Toward solving those problems, in this paper, we propose a memory-augmented sparse attention block utilizing bilinear pooling to capture the higher-order interactions between the input fine-grained image features while producing sparse attention. Moreover, we introduce a novel Medical Concepts Generation Network (MCGN) to predict fine-grained semantic concepts and incorporate them into the report generation process as guidance. Our proposed method shows promising performance on the recently released largest benchmark MIMIC-CXR. It outperforms multiple state-of-the-art methods in image captioning and medical report generation.
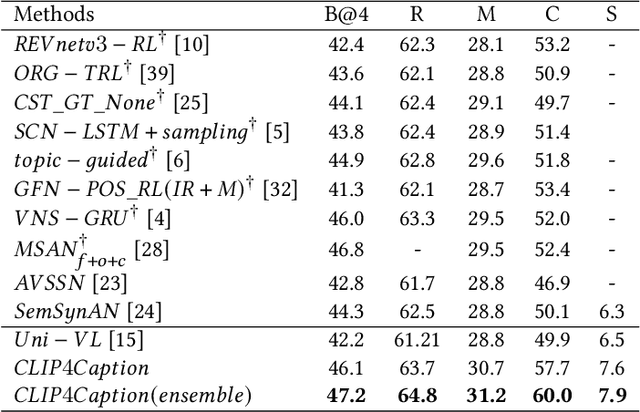
CLIP4Caption ++: Multi-CLIP for Video Caption
Oct 14, 2021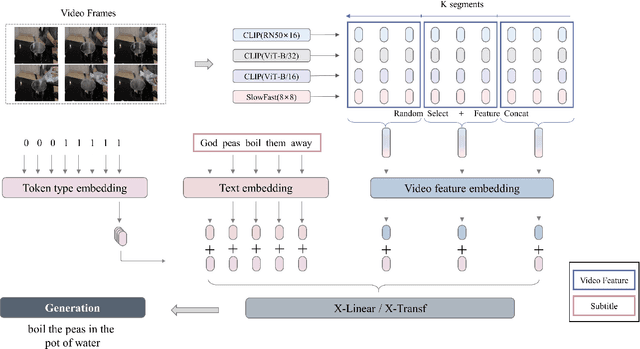
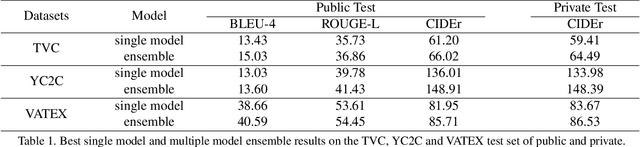

This report describes our solution to the VALUE Challenge 2021 in the captioning task. Our solution, named CLIP4Caption++, is built on X-Linear/X-Transformer, which is an advanced model with encoder-decoder architecture. We make the following improvements on the proposed CLIP4Caption++: We employ an advanced encoder-decoder model architecture X-Transformer as our main framework and make the following improvements: 1) we utilize three strong pre-trained CLIP models to extract the text-related appearance visual features. 2) we adopt the TSN sampling strategy for data enhancement. 3) we involve the video subtitle information to provide richer semantic information. 3) we introduce the subtitle information, which fuses with the visual features as guidance. 4) we design word-level and sentence-level ensemble strategies. Our proposed method achieves 86.5, 148.4, 64.5 CIDEr scores on VATEX, YC2C, and TVC datasets, respectively, which shows the superior performance of our proposed CLIP4Caption++ on all three datasets.
CLIP4Caption: CLIP for Video Caption
Oct 13, 2021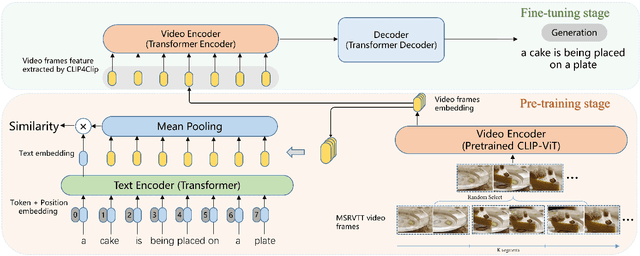

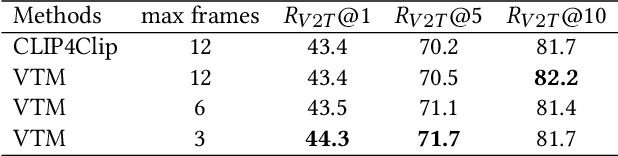
Video captioning is a challenging task since it requires generating sentences describing various diverse and complex videos. Existing video captioning models lack adequate visual representation due to the neglect of the existence of gaps between videos and texts. To bridge this gap, in this paper, we propose a CLIP4Caption framework that improves video captioning based on a CLIP-enhanced video-text matching network (VTM). This framework is taking full advantage of the information from both vision and language and enforcing the model to learn strongly text-correlated video features for text generation. Besides, unlike most existing models using LSTM or GRU as the sentence decoder, we adopt a Transformer structured decoder network to effectively learn the long-range visual and language dependency. Additionally, we introduce a novel ensemble strategy for captioning tasks. Experimental results demonstrate the effectiveness of our method on two datasets: 1) on MSR-VTT dataset, our method achieved a new state-of-the-art result with a significant gain of up to 10% in CIDEr; 2) on the private test data, our method ranking 2nd place in the ACM MM multimedia grand challenge 2021: Pre-training for Video Understanding Challenge. It is noted that our model is only trained on the MSR-VTT dataset.